Collaborative Filtering for Implicit Feedback Datasets 리뷰
논문 링크 : http://yifanhu.net/PUB/cf.pdf
코드 링크 : https://github.com/benfred/implicit
해당 논문은 2008년도에 작성 되었습니다.
추천 시스템의 명확한 피드백이 아닌 내재되어 있는 피드백에 대하여 다룬 논문 입니다.
명확하다는 것은 예를 들어서 1-5점, 구매 유무가 될수 있을듯 하고 내재되어 있는 피드백은 유저의 체류 시간 등이 될 수 있습니다.
해당 모델의 이전 모델은 KNN같은 Neighbor 모델인걸로 보아서 최초의 approach로 보입니다.(아닐수도!)
아래가 해당 논문의 수식 입니다.
u : 유저
i : 아이템
Xu : 유저 벡터
Yi : 아이템 벡터
R : 유저가 해당 아이템을 2번 보면 2. 70% 정도 보면 0.7이다.
P(preference) : 해당 유저가 해당 아이템을 사용하였으면 1 or 0
이는 유저 u, 아이템 i의 내적으로도 표현이 가능하다고 함.
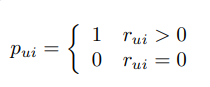
C(confidence) : 그냥 TV를 봤기 때문에 채널을 보았거나, 나는 싫어하지만 친구 선물을 위해 주는 경우를 처리하기 위해서 만들어 졌다고 한다.

관측값 - 예측값을 최소화 하는 전형적인 수식으로 볼 수 있음.
아래의 수식이 word2vec(glove), mf등에서 자주 사용되는 형식이라고 합니다.








코드 링크 : https://github.com/benfred/implicit
해당 논문은 2008년도에 작성 되었습니다.
추천 시스템의 명확한 피드백이 아닌 내재되어 있는 피드백에 대하여 다룬 논문 입니다.
명확하다는 것은 예를 들어서 1-5점, 구매 유무가 될수 있을듯 하고 내재되어 있는 피드백은 유저의 체류 시간 등이 될 수 있습니다.
해당 모델의 이전 모델은 KNN같은 Neighbor 모델인걸로 보아서 최초의 approach로 보입니다.(아닐수도!)
아래가 해당 논문의 수식 입니다.
u : 유저
i : 아이템
Xu : 유저 벡터
Yi : 아이템 벡터
R : 유저가 해당 아이템을 2번 보면 2. 70% 정도 보면 0.7이다.
P(preference) : 해당 유저가 해당 아이템을 사용하였으면 1 or 0
이는 유저 u, 아이템 i의 내적으로도 표현이 가능하다고 함.

C(confidence) : 그냥 TV를 봤기 때문에 채널을 보았거나, 나는 싫어하지만 친구 선물을 위해 주는 경우를 처리하기 위해서 만들어 졌다고 한다.
수식
뒤의 term은 regularization을 위함.관측값 - 예측값을 최소화 하는 전형적인 수식으로 볼 수 있음.
아래의 수식이 word2vec(glove), mf등에서 자주 사용되는 형식이라고 합니다.
최적화
최적화는 alternating-least-square 방법으로 진행하였으며 아래의 수식을 번갈아 계산 하는데 이는 얼핏 보면 원래의 식에서 각각을 추출해낸 것으로 짐작할 수 있다.
해당 논문에서는 데이터가 매우 커져서 SGD를 사용하지 않았다고 합니다. xu를 업데이트 하는데에 있어서 다른 변수와 연관성이 없기 때문에 병렬로 계산이 가능하다고 합니다. 또는 당시에 SGD가 유세하지 않았을수도 있다고 합니다.


아래의 C는 rui를 통해서 다시 표현할 수 있다고함. 로그 씌우기 용도인가?

평가 수식은 아래와 같은 새로운 rank라는 측도를 사용함. 0이면 best고 100이면 worst.
50이 나오는 것은 절반정도에 예측한것으로 랜덤의 결과라고 함.
rankui는 유저 u에게 아이템 i가 예측된 정도의 퍼센트
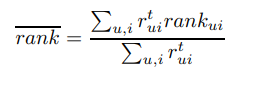
결과
Popularity는 단순히 인기순인듯. 인기순을 어떻게 뽑나 생각도 되지만 대충 조회수?
Neighborbood는 아이템들간의 KNN을 구한듯.
Factor는 사용된 파라미터의 갯수를 나타내는듯
Factor는 사용된 파라미터의 갯수를 나타내는듯
Figure 1 : 두 base 모델 모두 50%보다는 좋지만 우리것이 더 좋다! 라는 결과
Figure 2 : 아래는 top x를 얼마나 잘 맞췄나를 나타내는 지표.
Figure 3 : 15는 가장 인기 많음. 1는 가장 인기 많음을 나타낸다. 파란선은 해당 TV 쇼가 얼마나 인기가 있었고 예측되었는지를 나타내는데 15와 1의 차이가 극명확하게 나고 있다.
빨간색선은 유저의 시청 시간인데 예측되는 값의 차이가 별로 크지 않았고 이는 기대와는 다르다고 한다.



댓글
댓글 쓰기