if kakao 2일차 AI 후기 공유
세부 내용들은 추후 if.kakao.com에 올라오면 확인 가능하십니다.
2일차 2019 08 30 코엑스
키노트
오전 10시
카카오 AI
2018 외부 확장2019 kakao i엔진을 모바일에서도 사용
현대 자동차와 연계
블루투스 연계
이전에는 AI 인터페이스 → 확장을 했다면 이제는 사용자의 needs
interactive ai
단순한 질문 쿼리를 연장해서 상호 작용 하도록
MRC : 사람처럼 하기 위함.
minimi : small talk. 심심해 → 노래를 듣는건 어떨까요? 이런거
아직 딥러닝으로는 잘 안되고 있어서 rule based로 하고 있음.
simpson : 질문 답변과의 유사도를 통해서 고객 센터 일을 진행.
rule based → conversational ai → contextual ai
DFLO : 기존 인터페이스 AI의 한계를 처리하고 고도화
그라운드 X
블록체인디지털 농노제
cambridge analytica가 페이스북 데이터를 긁어와서 선거에 사용.
개인정보 보호법 EU
데이터 노동. 데이터를 통해서 우리도 경제적으로 분배 받아야 한다.
이렇게 정보를 개인화 해야하며 블록 체인 기반의 게임에서는 진행 되고 있다.
디지털 사진의 재산화 코닥에서 진행중.
디지털 아이템은 복제가 가능 → 블록 체인을 통해서 해결.

첫번째 결과가 klaytn 대규모 서비스. 기업에 최적화.
빠른 속도와 확장성 4000tps 하이브리드 블록 체인
금융 사기 잡는 카카오뱅크의 데이터 사이언스
FDS
카카오의 데이터 사이언티스트
금융 평가 등
 |
| 데이터 사이언스의 역할 |
금융 사기 스미싱 보이스피싱 파밍 대포 통장 등등.
이런 사기를 예방하기 위해서 FDS를 구축
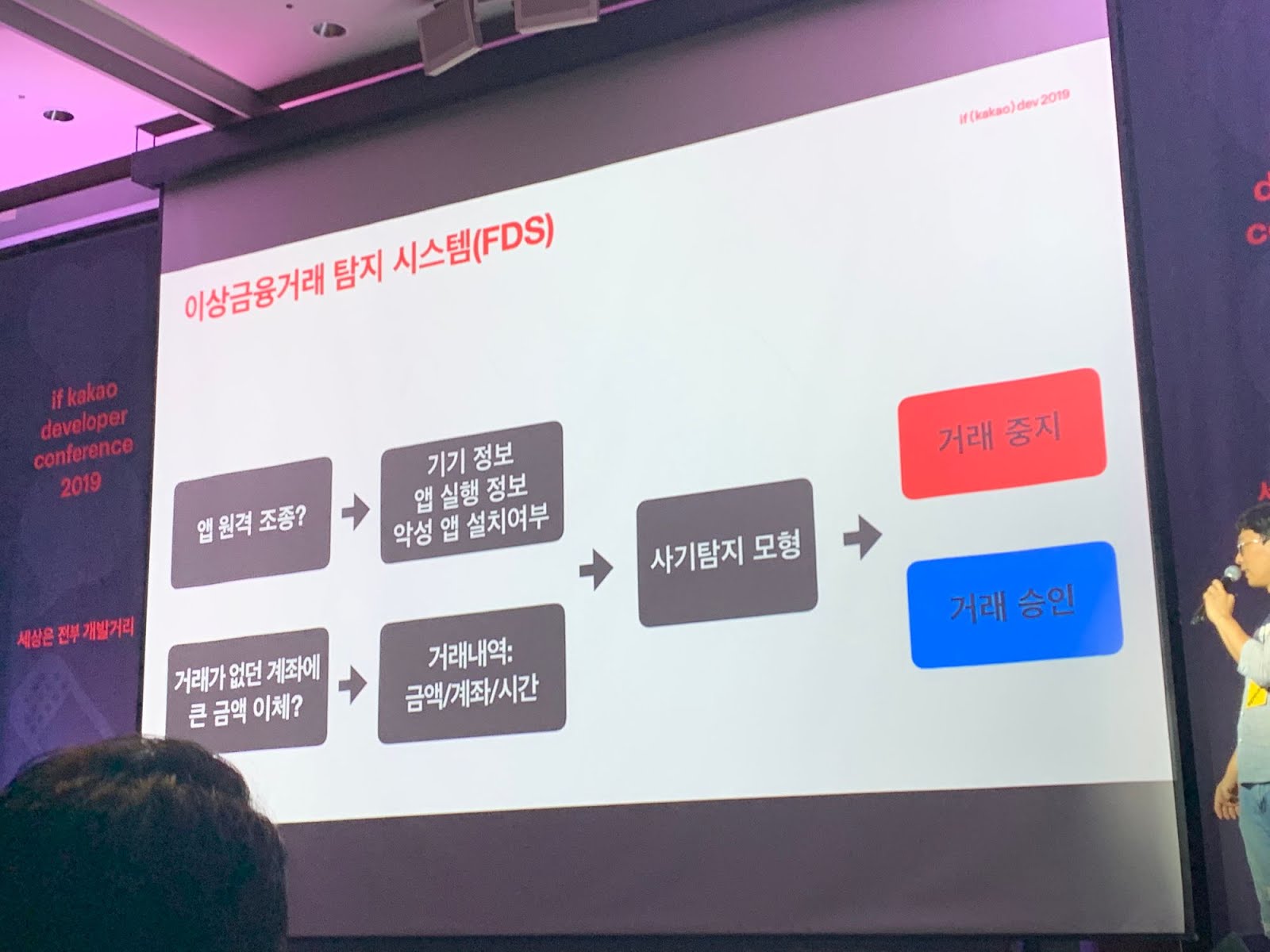 |
| FDS |
전자 금융 FDS와 체크카드 FDS
 |
| 기계 학습 활용 |
시계열 기반 사기 탐지.
사기 데이터가 1프로 미만이기 때문에 비율을 맞춰야함
아래와 같이 임베딩을 하고 ANN을 통하여 클러스터링을 한다. 클러스터 결과를 통해서 얻은 사기 데이터 들을 VAE를 통해서 Augmentation을 하고 이를 학습에 사용 한다.
 |
| 사기 데이터 생성 |
 |
| 앱 활동 벡터화 |
 |
| 데이터 벡터화 |
 |
| Auto-Encoder |
auto encoder를 통하여 감지를 하면 정확도는 더 높아지지만 다 잡을수는 없음..
데이터 샘플링 loss 조절 이벤트 벡터화를 통해서 성능 개선
결론으로는 딥러닝만으로는 답이 아님
아래와 같이 새로운 기법들을 시도중에 있음.
 |
| 최근 실행중인 기법들 |
TDA
데이터를 시각화하는 알고리즘인것으로 보임.
 |
| TDA |
원본 데이터를 가로 축으로 잘 분리. 이때 서로 겹치게 분리한다음 시각화?
 |
| K-means 시각화 |
 |
| 캐클 Competition 시각화 |
상세하게는 알기 힘들지만 개략적으로는 볼 수 있음.
서로다른 2개의 사기가 보임
 |
| 카카오 뱅크 시각화 |
질문
데이터 비율 문제가 있다고 하는데 샘플링 loss비율 부분 더 자세히 부탁.→ 답은 없는거같고 직접 배율을 수정해나가면서 비율 조정
데이터를 생성할수도 있는데 어떻게 하셨는지. 신규 사기는 어떻게 처리하셨는지 k means는 신규 사기는 못잡을것 같음.
→ 직접 데이터를 보기도 하고 금융권이기에 새로운 사기는 사례가 공유가 됨.
선행 연구인지 실제로 현업에 돌아가고 있는지
→ 탐지 등은 실제로 돌아감. 대응이 자동으로 될수 없는 부분은 전문적으로 처리하는 분들이 있음. 사기 아닌데 사기라고 되면 안되니까.
오토 인코더 Threshold가 중요할텐데 어캐 하셨는지
→ 이것만으로는 완벽히 탐지가 되지 않고 참고 자료로만 사용함.
Vae를 할때 비정형 데이터가 복호화가 잘 안되던데 어땟나요
→ 가공된 데이터를 써서 문제가 된적은 없음.
버팔로 추천 시스템 오픈소스
확장 가능, 편리한 추천 시스템
공개한지 2일.

최적화 되어 있음 데이터 베이스 크기에 무관함
추천시스켐은 협업 필터링 보다는 소비 경험에 중점.
시중에 있는 오픈소스는 카카오의 크기, 자원에 맞지 않았음.
버팔로는 MF를 엮은 라이브러리임.
알고리즘 als word2vec cofactor 베이지안 개인화 등을 지원
MF는 데이터를 줄이고 숨겨진 특성을 파악함
아래와 같이 행렬의 크기를 줄이고 중간에 특성을 반영함.
 |
| Matrix Factorization |
카카오의 대부분의 문제는 확장성은 보장되어야 하지만 퀄리티는 양보가 가능함.
아래는 사용된 데이터
카카오 데이터는 10일 데이터라 확장성이 없으면 기회를 잃게됨.
 |
| 데이터 |
버팔로는 카카오 추천 시스템의 전체에 비하여 일부인데 버팔로를 최적화하는것보다는 다른일을 하는게 더욱더 생산성이 좋을수 있음.
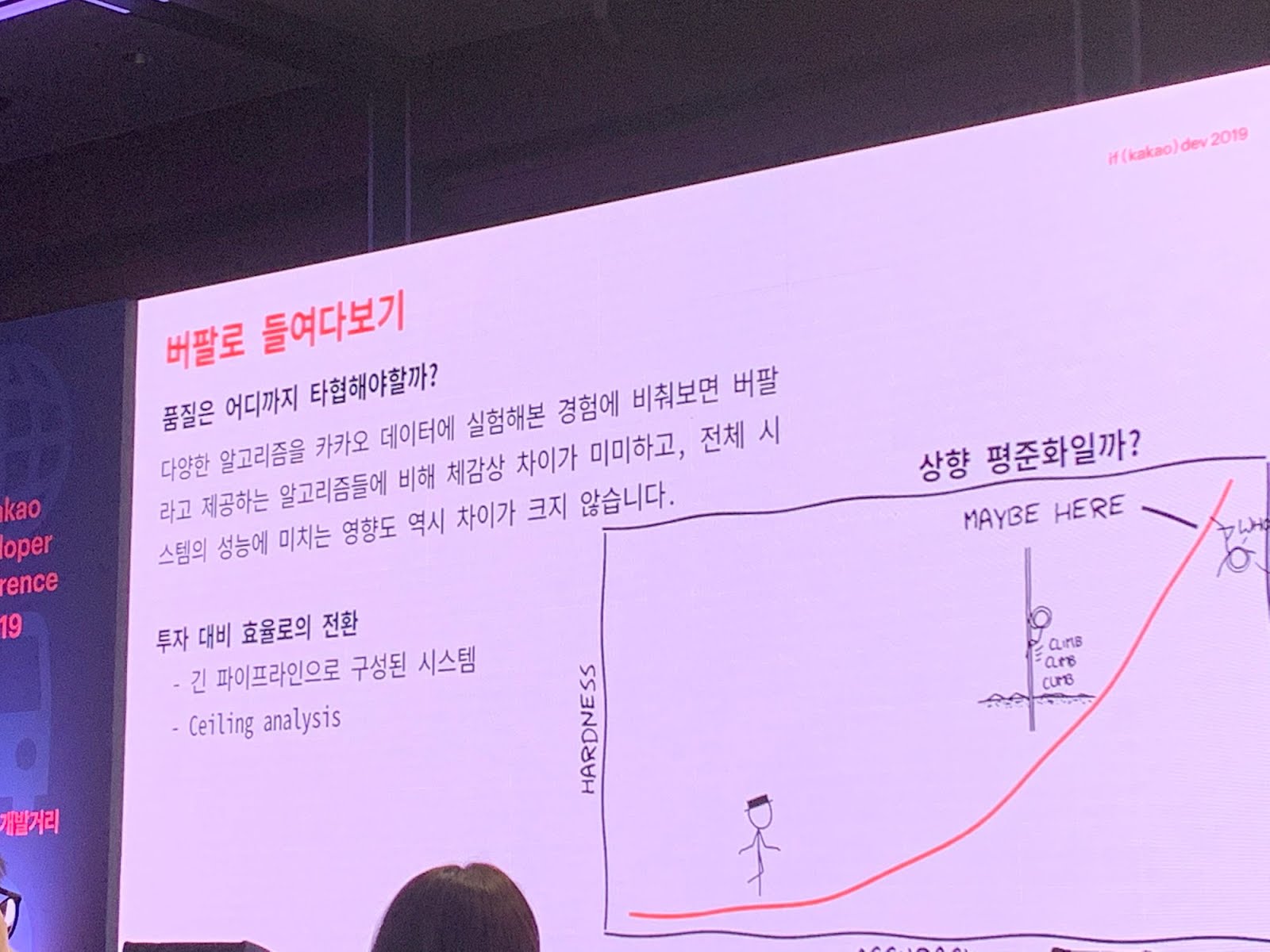 |
| 품질과의 타협 |
스파크 qmf implicit lightfm과 비교함
아래는 실행 시간 비교.
버팔로가 다른 오픈소스에 비하여 월등히 좋다.
 |
| 실행 시간 비교 |
 |
| GPU 벤치마킹 |
코어가 늘어남에 따라 선형적으로 증가
 |
| 코어 갯수 벤치마킹 |
배치 러닝이 가능. 데이터가 커도 무관.
메모리를 계속 넣은다고 해서 성능이 올라가는게 아님.
IO가 커지기 때문.
 |
| 메모리에 따른 성능 변화 |
실제로 돌리면 가장 어려운 부분은 매우 작게 해도 오래 걸림. 대부분의 라이브러리가 이부분에서 병목임.
이를 위해서 병렬 모드를 지원
병렬 모드를 사용하면 비약적으로 빨라짐 n2.
 |
| 버팔로 생산성 |
데이터를 메모리가 아닌 스스디에 올리면 더 빨라짐
데이터는 행렬 or 스트림 형식을 지원
데이터를 분리하는것도 기능을 통해 지원.
평가를 빈칸 맞추기를 할수도 있고 최근 데이터를 맞출 수 있는데 이를 할수 있음..?
텐서 보드 연동
 |
| 텐서 보드 연동 |
하이퍼 파라미터 튜닝
하이퍼 옵트 라는 유명한 라이브러리를 사용하였음.
 |
| 하이퍼 파라미터 최적화 |
마무리
 |
| 마무리 |
카카오와 다음의 컨텐츠 분류
데이터 운영, fasttext
지금도 분류가 되는중
 |
| 분류 |
발표 대상은 서비스에서 머신러닝을 통하여 분류하고 싶은 사람.
포털의 역할
 |
| 포털의 역할 |
카테고리를 고르는데 시간이 너무 걸림.
그래서 자동 분류 데이터를 분석도 가능.
 |
| 자동 분류가 필요 하다 |
분류 체계를 외부 수집
 |
| 외부 수집 |
컨텐츠 구성 여러 경우의 수를 따진다.
 |
| 컨텐츠 구성 |
카테고리의 관계 감정형 카테고리
구축자들관에 논의
 |
| 분류가 어려운 카테고리들 |
그후에는 데이터 구축
모델 검증
이때 아래 모델중 이상한 모델을 검토.
이를 계속 반복
 |
| 모델 검증 |
카테고리의 갯수를 잘 조절해야함.
많다고 좋은게 아니더라
 |
| 카테고리 갯수 |
정확도보다 데이터의 수가 중요.
 |
| 데이터 수의 중요도. |
좋은 데이터 필요. 몇만개. 전문가 필요.
학습 데이터 관리
 |
| 자동화의 필요성 |
어드민
 |
| 어드민을 개발 하자 |
관리 어드민 버전 관리.
 |
| 어드민 개발 |
학습 데이터의 2가지 측면에서의 관리를 해야한다.
 |
| 정확도 시각화 |
학습셋 관리. 틀린 데이터는 운영자가 데이터를 변경 한다.
 |
| 학습셋 관리 |
학습 모델 FastText
도메인에 따라 좋은 모델은 다름. |
| 좋은 분류 모델 |
알고리즘 비교
 |
| 테스트 알고리즘 비교 |
사용하고 있는 알고리즘
 |
| 사용하고 있는 알고리즘 |
카카오 라는 단어 자체를 학습 가능.
 |
| Character N-gram |
가성비 좋음
 |
| 캡션 추가 |
3개 층의 단순 신경망 구조임
 |
| FastText 구조 |
지도식 학습 소프트맥스 하이라리컬 소프트맥스 네거티브 샘플링
네거티브 샘플링은 정답 오답 일부에 대하여 학습. 오답 갯수를 지정해야함.
 |
| Negative Sampling |
텍스트가 별로 없고 이미지만 있거나 이미지에 텍스트가 있으면 현재로썬 어렵다.
머신러닝의 한계가 있다. 유머성 데이터는 카테고리와 거의 무관한 부분이 있다. Cold Start 문제 또한 존재.
 |
| 한계 |
여러 머신 러닝을 적용. 머신러닝들이 룰베이스를 이길 수 있도록 설정.
 |
| 종합 예측 |
비율
룰 매핑이 은근히 많다.
 |
| 종합 결과 비율 |
어드민 관리
컨퓨전 매트릭스의 각 케이스를 클릭하면 상세 정보를 볼 수 있다.
 |
| 컨퓨전 매트릭스 |
시계열 정확도 대시보드
 |
| 시계열 대시보드 |
모델 관리 또한 어드민 시스템을 통하여 한다.
 |
| 모델 비교 |
후기
도메인 분석 필요, 학습셋 관리, FastTest가 빠르다.
 |
| 후기 |
상품 카탈로그 자동 분류

카탈로그란 검색 결과에서 최저가를 보여주는 그것을 말함.
 |
| 카탈로그 |
상품 정보를 좀더 유저가 보기 쉽도록 정제할 필요가 있음.
 |
| 카탈로그 |
검색의 24퍼는 쇼핑. 쇼핑의 60퍼는 검색
검색의 대부분은 좀더 탐색하는 목적형 검색.
이들을 잡는것은 중요하다.
 |
| 검색 트래픽 |
카탈로그 자동 생성
시즌과 트렌드에 민감한 신발 의류, 사회적 이슈에 따라 증가하는 제품이 많다.
따라서 이를 직접 대응하기 힘어 자동화가 필요 하다.
따라서 이를 직접 대응하기 힘어 자동화가 필요 하다.
 |
| 상품과 카탈로그 |
포털, 쇼핑 플랫폼에서 가이드를 주어도 판매자들이 잘 따르지는 않는다.
아래와 같이 카드 할인, 당일 배송 키워드는 그 키워드로 검색하는 사람이 없기도 하고 제품 설명에 라벨을 붙여줘서 전혀 필요가 없는 태그 이다.
 |
| 불필요한 정보 |
같은 제품이라도 이미지, 제품 이름, 가격, 카테고리가 약간씩 다르기 때문에 유사도를 판단하여 같은 제품임을 파악할수 있어야 한다.
 |
| 카탈로그 동일성 파악 |
모델 구조
카테고리를 통해서 분류를 하고 상품 정보들을 임베딩 하여 유사도를 판단한다. 결과로 나온 유사도 벡터를 통해서 같은 제품끼리 묶는 Label Propagation을 진행 한다.

이미지 분류 또한 아래와 같이 VGG 19 모델을 통해서 벡터화를 한다.

같은 제품이라도 순서가 다를 수 있으며 제품명, 제품과 관련 없는 키워드가 들어갈 수 있다.
 |
| 임베딩 특징 |
CNN, RNN을 통해서 처리하지 않고 TF-IDF 알고리즘을 사용하였다고 한다. 이는 각 자리의 특징이 무의미 하기 때문이라고 함.
 |
| TF-IDF |
벡터를 통해서 KNN을 통해서 유사 상품을 묶을 수 있다.

그런데 그냥 묶으면 아래와 같은 문제가 발생할 수 있다.
- 다른 상품인데 임베딩이 비슷함.
- 같은 상품인데 다른 임베딩임
- 근사 knn이라 정확도가 다를 수 있음.
따라서 이를 처리하기 위해서 그래프 알고리즘을 사용하였다고 한다.
 |
| Community Detection |
Label Propagation 알고리즘을 사용하였고 이는 속도가 빨라서 사용하였다고 한다.
 |
| Label Propagation |
아래는 알고리즘 돌아가는 순서 이다.
각 노드마다 랜덤으로 순서를 지어서 각 노드에 인접한 노드들의 카탈로그에 가장 많은 카탈로그로 내 카탈로그를 결정한다.
 |
| Algorithm |
성능을 측정해야 하니 아래와 같이 Edge Proportion 수식을 사용하였다고 한다.
이는 각 상품들이 연관된 정도라고 볼 수 있다.
 |
| Edge Proportion |
최적화
최적화 하기 위해서 그래프의 크기를 줄임. 같은 이름은 하나로 뭉치고 서머리 해주는 알고리즘 사용.
알고리즘 순회를 한번에 여러개 순회 하도록 병렬화
질문
임베딩 업데이트 주기는?→ 실시간
이미지 텍스트 벡터를 합치기도 하나요?
→ 아닙니다. 따로 그래프 각각 만듭니다.
데이터 관점 카카오 광고의 실질적인 문제들

작년에는 카카오의 광고 지능.
 |
| 광고의 전반적인 구조 |
광고를 게제하는 웹사이트를 담당하는 Publisher
광고를 올리고 싶어하는 Advertiser 등의 이해 관계가 있다.
광고주가 광고를 관리하는 대시보드는 DSP
Publisher가 내 사이트에 올라갈 광고를 관리하는 부분은 SSP
적절한 광고를 보내주는 부분은 DMP 라고 한다.
이전까지의 광고가 단순히 구좌에 보여주는 것을 다뤘으면 현재의 광고는 성과를 위해 타겟팅 하는것 까지 영역이 확장되어 있다.
LookAlike - 전환률이라는 듯
 |
| 타게팅 |
데이터상 한사람이 많아야 500건을 보고 대부분이 1000개 정도의 광고가 95%의 노출을 가짐. 광고 소재는 50만개
유저 임베딩. 그냥 냅두면 차원이 너무 높음.
LDA를 통해 차원을 줄임 svd는 계산량이 너무 많음.
차원을 줄이는 정도는 경험적으로 해야함.
차원을 줄이면 어떤 사람이 어떤것을 줄이다 라는 것을 없에서 개인정보 보호 가능 그렇지만 설명력이 떨어져서 cs 대응 불가.
Pca는 쓸때마다 semantic이 바뀜 lda는 가능
토픽 갯수는 30개 사용.
딥러닝 방식 pCTR
딥러닝 임베딩 후 예측.원핫 인코딩 32= 우리가 경험적으로 얻은 32
레이어는 2에서 좋은듯.
장점 정확함 원샷 가능
단점
콜드 스타트
하이퍼파라미터 학습 데이터
해석 가능성
서빙 속도
구매 전환
요즘은 구매 전환 까지 cs가 들어옴.전환이 빨리 되기도 하지만 늦게 되기도 함.
딜레이 타임을 적용한 모델이 있고 적용하니까 좋아짐. 딜레이도 파라미터로 넣음.
메이저 기업은 전환이 많지만 그렇지 않으면 적음
다이나믹 크리에이티브 옵티마이져
생략자동입찰
자동입찰이라는게 정해진 단어가 아니다 보니 일정 기간동안 얼마를 입찰한다거나 특정 지면에 지속적으로 입찰한다거나 하는등 업체마다 다른듯 한데 카카오에서 해석하는 자동입찰은 자동적으로 자신에게 최적인 전략을 통해서 입찰을 하는듯 하다. |
| 자동 입찰의 흐름 |
아래 그래프는 자동 입찰이 고정가 입찰에 비하여 성능이 좋다고 비교한 그래프 이다. 그렇다고 모든 경우에 자동입찰이 좋은것은 아니다. 이는 성과가 클릭에 국한되지 않고 노출이 많아야 하는 경우에는 CPM 광고라는 노출이 보장되는 광고에 유리할 수 있다.
 |
| 자동 입찰의 성과 |
그외
들어오는 데이터에만 학습하니까 랜덤 데이터도 생성또한 샘플링을 함. 클릭 데이터는 적으니까 클릭된거는 모두 살림. Negative down sampling.
테스트
오프라인 후 온라인 테스트
테스트는 a/b 테스트 방식
CTR을 올렸으나 수익은 변동이 없는 경우가 있음.
Q&A
날씨 요일등 사용합니까?→ 날씨는 인과관계를 규명하기 힘듬. 요일은 사용중.
어뷰징은?
→ ssp에서도 가짜 트래픽을 만듬. 이 이후는 영업 기밀.
그외 사진
아래의 에코벡 등은 입장할때 수령하였습니다.카카오 부스등에서 스티커 등을 수령할 수 있던거 같은데 부스에 방문하지는 않았습니다.
 |
| 입장때 받은 굿즈 |
굿즈에 포함된 카카오 생수
 |
| 카카오 생수 |
나만의 프로필 이벤트.
Myeongjoon으로 하려고 하였는데 6자리 제한이 있어서 회사 이름을 사용 mgim
 |
| mgim |
포토스팟
코엑스 세미나 하는곳 입장하면 바로 보이는 그곳
 |
| 포토스팟 |



댓글
댓글 쓰기